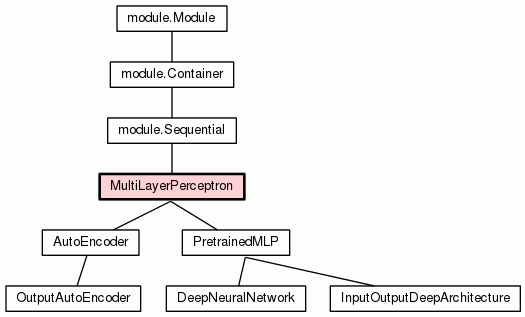
A MLP must be trained with a supervised learning algorithm in order
to work. The gradient backpropagation is by far the most used algorithm
used to train MLPs.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| defaultLearningParameters(self,
param_dict) |
source code
|
|
|
|
finetune(self,
shared_x_train,
shared_y_train,
batch_size,
learning_rate,
epochs,
growth_factor,
growth_threshold,
badmove_threshold,
verbose)
Performs the supervised learning step of the MultiLayerPerceptron,
using a batch-gradient backpropagation algorithm. |
source code
|
|
|
|
|
|
Inherited from module.Sequential:
prepareGeometry,
prepareOutput,
prepareParams
Inherited from module.Container:
add
Inherited from module.Module:
criterionFunction,
forward,
forwardFunction,
holdFunction,
linkInputs,
linkModule,
prepare,
prepareBackup,
restoreFunction,
save,
trainFunction
|